
বাংলাদেশের একজন শিক্ষক হিসেবে আপনি হয়তো জানেন—মানসম্মত প্রশ্নপত্র তৈরি, পাঠ পরিকল্পনা প্রণয়ন, আর ক্লাসের জন্য কন্টেন্ট তৈরি করতে কতটা সময় লাগে। ChatGPT বা অন্যান্য AI টুলস ব্যবহার করে এই কাজগুলো সহজ করা যায়—কিন্তু সমস্যা হলো, এই টুলসগুলো বাংলাদেশের NCTB কারিকুলাম সম্পর্কে বিস্তারিত জানে না। ফলে তারা এমন কন্টেন্ট তৈরি করে যা অনেক সময় সিলেবাসের বাইরে চলে যায়, ভুল তথ্য দেয়, অথবা আমাদের পাঠ্যপুস্তকের সাথে মিলে না।
এই সমস্যার সমাধান নিয়ে এসেছে লেসনকিটস্। কিন্তু লেসনকিটস্ কীভাবে এই সমস্যার সমাধান করে? কীভাবে এটি নিশ্চিত করে যে তৈরি করা কন্টেন্ট NCTB কারিকুলামের সাথে সামঞ্জস্যপূর্ণ এবং ভুল তথ্যমুক্ত?
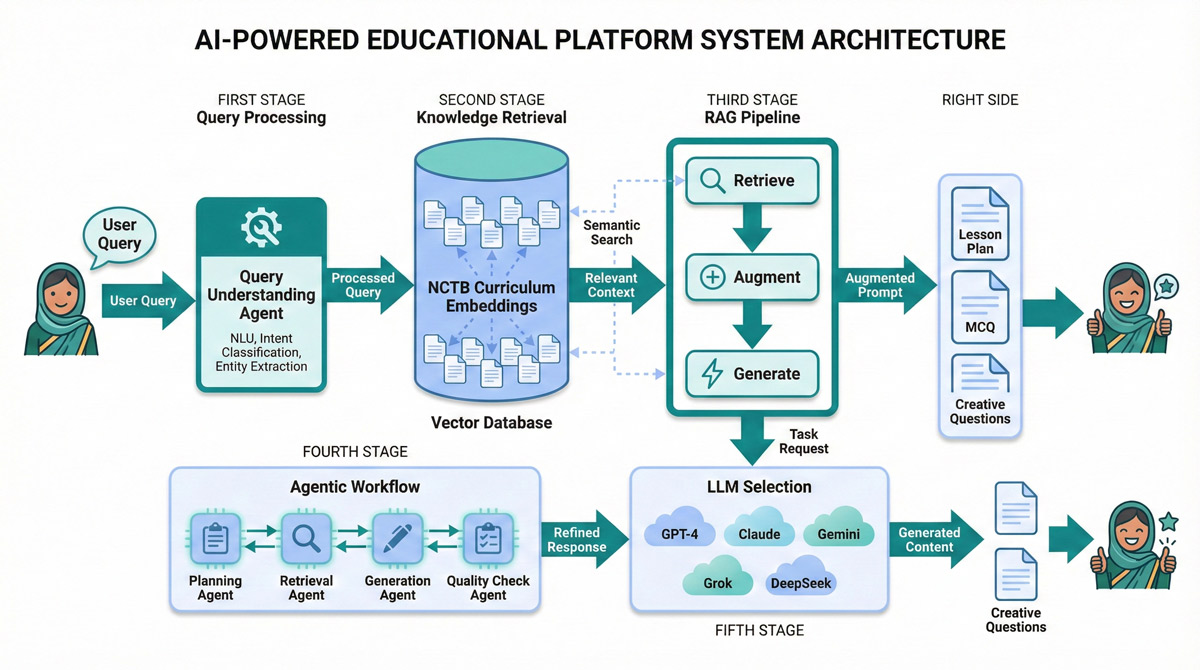
এই ব্লগ পোস্টে আমরা লেসনকিটস্-এর প্রযুক্তিগত কাঠামো নিয়ে আলোচনা করব—বিশেষত Vector Database, RAG (Retrieval Augmented Generation), এবং Agentic Workflow কীভাবে একসাথে কাজ করে শিক্ষকদের জন্য নির্ভুল ও প্রাসঙ্গিক কন্টেন্ট তৈরি করে।
সাধারণ AI টুলসের সীমাবদ্ধতা
ChatGPT, Gemini, বা Claude-এর মতো Large Language Model (LLM) গুলো অত্যন্ত শক্তিশালী। এরা বিশ্বের বিভিন্ন ভাষায় কথা বলতে পারে, জটিল গণিত সমাধান করতে পারে, কোড লিখতে পারে। কিন্তু একটি বড় সমস্যা আছে—এই মডেলগুলো বাংলাদেশের জাতীয় শিক্ষাক্রম ও পাঠ্যপুস্তক বোর্ডের (NCTB) কারিকুলাম সম্পর্কে বিস্তারিত জানে না।
যখন আপনি ChatGPT-কে বলেন "নবম শ্রেণির পদার্থবিজ্ঞান থেকে গতি অধ্যায়ের উপর ৫টি সৃজনশীল প্রশ্ন তৈরি করো"—তখন সে হয়তো প্রশ্ন তৈরি করবে, কিন্তু সেগুলো NCTB পাঠ্যপুস্তকের বিষয়বস্তুর সাথে নাও মিলতে পারে। অনেক সময় সিলেবাসের বাইরের টপিক অন্তর্ভুক্ত হয়ে যায়, ভুল তথ্য চলে আসে, অথবা বাংলাদেশের পরীক্ষা পদ্ধতির ফরম্যাট অনুসরণ করা হয় না।
এই সমস্যাকে AI-এর ভাষায় বলা হয় "Hallucination"—অর্থাৎ AI এমন তথ্য তৈরি করে যা বাস্তবে নেই বা ভুল। LLM-গুলো মূলত Pattern Recognition-এর মাধ্যমে কাজ করে। তারা প্রশিক্ষণের সময় যে টেক্সট দেখেছে, সেগুলোর প্যাটার্ন অনুসরণ করে নতুন টেক্সট তৈরি করে। কিন্তু যখন কোনো নির্দিষ্ট বিষয়ে (যেমন NCTB কারিকুলাম) তাদের প্রশিক্ষণ ডেটায় পর্যাপ্ত তথ্য থাকে না, তখন তারা "অনুমান" করে উত্তর দেয়—যা প্রায়ই ভুল হয়।
তাহলে সমাধান কী? AI-কে প্রতিটি প্রশ্নের উত্তর দেওয়ার সময় NCTB কারিকুলামের প্রাসঙ্গিক তথ্য সরবরাহ করতে হবে। আর এখানেই লেসনকিটস্-এর RAG প্রযুক্তি কাজে আসে।
লেসনকিটস্-এর জ্ঞানভাণ্ডার
লেসনকিটস্-এর মূল ভিত্তি হলো এর সমৃদ্ধ জ্ঞানভাণ্ডার। এই জ্ঞানভাণ্ডারে NCTB কারিকুলাম অনুযায়ী বিভিন্ন শ্রেণি ও বিষয়ের সিলেবাস, পাঠ্যপুস্তকের বিষয়বস্তু, অধ্যায়ভিত্তিক শিখনফল, এবং প্রশ্নের নমুনা সংরক্ষিত আছে। কিন্তু এই তথ্যগুলো সাধারণ ডাটাবেসে রাখা হয়নি—এগুলো রাখা হয়েছে একটি বিশেষ ধরনের ডাটাবেসে যাকে বলা হয় Vector Database।
Vector Database বোঝার জন্য প্রথমে বুঝতে হবে "Embedding" কী। যখন আমরা কোনো বাক্য বা অনুচ্ছেদকে একটি বিশেষ AI মডেলের (Embedding Model) মধ্য দিয়ে পাঠাই, তখন সেটি ঐ টেক্সটকে শত শত বা হাজার হাজার সংখ্যার একটি তালিকায় (Vector) রূপান্তর করে। এই সংখ্যাগুলো টেক্সটের "অর্থ" বা Semantic Meaning ধারণ করে।
উদাহরণস্বরূপ, "গতি হলো সময়ের সাপেক্ষে সরণের হার" এই বাক্যটিকে Embedding Model একটি Vector-এ রূপান্তর করে, যেমন: [0.23, -0.45, 0.67, 0.12, ...]। একই অর্থের অন্য বাক্য, যেমন "কোনো বস্তুর অবস্থানের পরিবর্তনের হারকে গতি বলে"—এটিও একই রকম Vector তৈরি করবে। দুটি Vector-এর মধ্যে গাণিতিক দূরত্ব (Cosine Similarity বা Euclidean Distance) পরিমাপ করে বোঝা যায় দুটি টেক্সট অর্থের দিক থেকে কতটা কাছাকাছি।
লেসনকিটস্-এ NCTB-এর সকল পাঠ্যপুস্তক ও সিলেবাসকে ছোট ছোট অংশে (Chunks) ভাগ করে প্রতিটি অংশকে Vector-এ রূপান্তর করা হয়েছে। এই Vector-গুলো একটি বিশেষ ডাটাবেসে সংরক্ষিত আছে যা অত্যন্ত দ্রুত Semantic Search করতে পারে। অর্থাৎ, যখন কেউ "রক্ত সংবহন" সম্পর্কে জানতে চায়, সিস্টেম শুধু "রক্ত সংবহন" শব্দটি খোঁজে না—বরং এই বিষয়ের সাথে অর্থগতভাবে সম্পর্কিত সকল তথ্য খুঁজে বের করে, যেমন হৃৎপিণ্ড, ধমনি, শিরা, রক্তচাপ ইত্যাদি।
RAG: Retrieval Augmented Generation
এখন আসা যাক লেসনকিটস্-এর সবচেয়ে গুরুত্বপূর্ণ প্রযুক্তিতে—RAG বা Retrieval Augmented Generation। এই পদ্ধতিতে AI মডেল উত্তর দেওয়ার আগে প্রথমে জ্ঞানভাণ্ডার থেকে প্রাসঙ্গিক তথ্য "Retrieve" বা খুঁজে আনে, তারপর সেই তথ্য দিয়ে নিজের জ্ঞানকে "Augment" বা সমৃদ্ধ করে, এবং সবশেষে উত্তর "Generate" করে।
এটিকে সহজভাবে বোঝার জন্য একজন গবেষকের কথা ভাবুন। তিনি যখন কোনো প্রশ্নের উত্তর দেন, তখন শুধু স্মৃতি থেকে বলেন না। প্রথমে লাইব্রেরিতে গিয়ে প্রাসঙ্গিক বই ও জার্নাল খোঁজেন, সেগুলো পড়েন, তারপর সেই তথ্যের ভিত্তিতে উত্তর তৈরি করেন। RAG ঠিক এই প্রক্রিয়াটিই AI-এর জন্য স্বয়ংক্রিয় করে।
লেসনকিটস্-এ RAG তিনটি ধাপে কাজ করে। প্রথম ধাপে, যখন একজন শিক্ষক অনুরোধ করেন "অষ্টম শ্রেণির বিজ্ঞান বই থেকে মানবদেহের রক্ত সংবহন অধ্যায়ের উপর ৩টি MCQ তৈরি করো", তখন সিস্টেম এই অনুরোধটিকে Vector-এ রূপান্তর করে এবং Vector Database-এ Semantic Search চালায়। এই Search-এ অষ্টম শ্রেণির বিজ্ঞান বইয়ের রক্ত সংবহন অধ্যায়ের সকল প্রাসঙ্গিক অংশ খুঁজে পাওয়া যায়।
দ্বিতীয় ধাপে, এই প্রাপ্ত তথ্যগুলো শিক্ষকের মূল অনুরোধের সাথে যুক্ত করে একটি সমৃদ্ধ Prompt তৈরি করা হয়। এই Prompt-এ থাকে মূল অনুরোধ, NCTB বই থেকে প্রাপ্ত প্রাসঙ্গিক তথ্য, এবং বিশেষজ্ঞ দ্বারা তৈরি System Instructions।
তৃতীয় এবং শেষ ধাপে, এই সমৃদ্ধ Prompt টি LLM-এ (যেমন ChatGPT, Claude, বা Gemini) পাঠানো হয়। এখন LLM শুধু নিজের সাধারণ জ্ঞান থেকে নয়, বরং NCTB পাঠ্যপুস্তকের প্রকৃত বিষয়বস্তুর ভিত্তিতে MCQ তৈরি করে। ফলে উত্তর সিলেবাসের মধ্যে থাকে এবং Hallucination-এর সম্ভাবনা অনেক কমে যায়।
Agentic Workflow: একাধিক AI এজেন্টের সমন্বিত কর্মপ্রবাহ
RAG-এর পাশাপাশি লেসনকিটস্ আরেকটি উন্নত পদ্ধতি ব্যবহার করে যাকে বলা হয় Agentic Workflow। সাধারণত আমরা একটি LLM-কে একটি Prompt দিই এবং সে একটি উত্তর দেয়। কিন্তু Agentic Workflow-তে একাধিক AI "এজেন্ট" বিভিন্ন ধাপে কাজ করে, যেখানে প্রতিটি এজেন্ট একটি নির্দিষ্ট কাজে বিশেষজ্ঞ এবং তারা নিজেদের মধ্যে তথ্য আদান-প্রদান করে সিদ্ধান্ত নেয়।
এই ধারণাটি বোঝার জন্য একটি প্রকাশনা সংস্থার কথা ভাবুন। সেখানে একজন লেখক সব কাজ করেন না। একজন গবেষক তথ্য সংগ্রহ করেন, একজন লেখক লেখেন, একজন সম্পাদক পর্যালোচনা করেন, একজন প্রুফরিডার ভুল সংশোধন করেন। প্রতিটি ধাপে বিশেষজ্ঞ ব্যক্তি কাজ করায় চূড়ান্ত ফলাফল অনেক বেশি মানসম্মত হয়।
লেসনকিটস্-এ এই Agentic Workflow বেশ কয়েকটি ধাপে কাজ করে। প্রথমে Query Understanding এজেন্ট শিক্ষকের অনুরোধ বিশ্লেষণ করে বোঝার চেষ্টা করে কোন শ্রেণি, কোন বিষয়, কোন অধ্যায়, এবং কী ধরনের কন্টেন্ট চাওয়া হচ্ছে। এরপর Knowledge Retrieval এজেন্ট Vector Database থেকে প্রাসঙ্গিক তথ্য খুঁজে আনে এবং সেগুলোর প্রাসঙ্গিকতা যাচাই করে। তারপর Content Generation এজেন্ট প্রাপ্ত তথ্য ও বিশেষজ্ঞ-নির্মিত Prompt ব্যবহার করে ব্যবহারকারীর নির্বাচিত Frontier Model-এ (ChatGPT, Claude, Gemini, Grok, বা DeepSeek) চূড়ান্ত কন্টেন্ট তৈরি করে।
এই Multi-Agent পদ্ধতির সুবিধা হলো প্রতিটি ধাপে সিদ্ধান্ত নেওয়া যায় এবং ভুল হলে সংশোধন করা যায়। একটি Single Prompt-এ সব কাজ করতে গেলে যে সীমাবদ্ধতা থাকে, Agentic Workflow সেটি অতিক্রম করে।
Frontier Model Integration: সেরা মডেলগুলোর সমন্বয়
লেসনকিটস্-এর আরেকটি বিশেষত্ব হলো এটি একাধিক Frontier Model-এর সাথে সংযুক্ত। Frontier Model বলতে বোঝায় AI গবেষণার সর্বশেষ এবং সবচেয়ে উন্নত মডেলগুলো, যেমন OpenAI-এর GPT-4o, Anthropic-এর Claude, Google-এর Gemini, xAI-এর Grok, এবং DeepSeek।
প্রতিটি মডেলের নিজস্ব শক্তি আছে। কেউ সৃজনশীল লেখায় ভালো, কেউ যুক্তিতে, কেউ বাংলা ভাষায়। লেসনকিটস্ ব্যবহারকারীকে তাদের পছন্দের মডেল বেছে নেওয়ার সুযোগ দেয়। কিন্তু গুরুত্বপূর্ণ বিষয় হলো, যে মডেলই ব্যবহার করা হোক না কেন, সবাই একই NCTB কারিকুলাম-ভিত্তিক Context পায় RAG-এর মাধ্যমে। ফলে সব মডেলই সিলেবাস-সামঞ্জস্যপূর্ণ কন্টেন্ট তৈরি করে।
এছাড়া, বিভিন্ন মডেলের API ব্যবহার করায় লেসনকিটস্ একটি সাশ্রয়ী মূল্যে সেবা দিতে পারে। যেখানে ChatGPT Plus-এর মাসিক খরচ প্রায় ২৪০০ টাকা, সেখানে লেসনকিটস্ Token-ভিত্তিক মূল্য নির্ধারণ করে, অর্থাৎ আপনি যতটুকু ব্যবহার করবেন ততটুকুই খরচ হবে।
চূড়ান্ত ফলাফল: শিক্ষকরা কী পান?
এই সম্পূর্ণ প্রযুক্তিগত প্রক্রিয়ার ফলাফল হলো শিক্ষকরা NCTB কারিকুলাম-সামঞ্জস্যপূর্ণ, মানসম্মত কন্টেন্ট পান অত্যন্ত সহজে। তাদের কোনো Prompt Engineering জানার দরকার নেই, AI মডেলকে কারিকুলাম বোঝানোর ঝামেলা নেই।
লেসনকিটস্ থেকে শিক্ষকরা তৈরি করতে পারেন সৃজনশীল প্রশ্ন যা NCTB ফরম্যাট অনুসরণ করে, বহু-নির্বাচনী প্রশ্ন (MCQ) যা সিলেবাসের মধ্যে থাকে, বিস্তারিত পাঠ পরিকল্পনা, কোর্স কনটেন্ট ও নোট, এবং শীঘ্রই প্রেজেন্টেশন স্লাইড ও ফ্ল্যাশ কার্ড।
কেন এই প্রযুক্তি গুরুত্বপূর্ণ?
সংক্ষেপে বলতে গেলে, লেসনকিটস্ তিনটি প্রযুক্তির সমন্বয়ে Hallucination সমস্যার সমাধান করে। Vector Database নিশ্চিত করে যে NCTB কারিকুলামের তথ্য সঠিকভাবে সংরক্ষিত এবং দ্রুত খোঁজা যায়। RAG নিশ্চিত করে যে AI মডেল উত্তর দেওয়ার আগে প্রাসঙ্গিক তথ্য পায়, ফলে অনুমান-নির্ভর উত্তরের বদলে তথ্য-নির্ভর উত্তর আসে। Agentic Workflow নিশ্চিত করে যে পুরো প্রক্রিয়াটি ধাপে ধাপে যাচাই-বাছাই হয়ে চূড়ান্ত ফলাফল তৈরি হয়।
এই প্রযুক্তির মাধ্যমে লেসনকিটস্ বাংলাদেশের শিক্ষকদের হাতে অত্যাধুনিক AI-এর শক্তি তুলে দিচ্ছে—সহজে, সাশ্রয়ী মূল্যে, এবং সবচেয়ে গুরুত্বপূর্ণ, NCTB কারিকুলামের সাথে পূর্ণ সামঞ্জস্য রেখে।
উপসংহার
AI প্রযুক্তি দ্রুত বিকশিত হচ্ছে এবং শিক্ষাক্ষেত্রে এর প্রয়োগ অপরিসীম সম্ভাবনা তৈরি করছে। কিন্তু শুধু শক্তিশালী AI মডেল থাকলেই হবে না—সেই মডেলকে স্থানীয় প্রেক্ষাপটে কার্যকর করতে হবে। লেসনকিটস্ ঠিক সেই কাজটিই করছে। Vector Database-এ NCTB জ্ঞান সংরক্ষণ করে, RAG-এর মাধ্যমে সেই জ্ঞান AI মডেলে সরবরাহ করে, এবং Agentic Workflow দিয়ে পুরো প্রক্রিয়াটি সুসংহত করে।
ফলাফল? বাংলাদেশের প্রতিটি শিক্ষক এখন বিশ্বমানের AI প্রযুক্তি ব্যবহার করে তাদের নিজস্ব কারিকুলাম অনুযায়ী কন্টেন্ট তৈরি করতে পারবেন। এটিই AI-এর প্রকৃত গণতন্ত্রায়ন—যেখানে প্রযুক্তি শুধু কিছু মানুষের জন্য নয়, সবার জন্য।

0 টি মন্তব্য
এখনও কোনো মন্তব্য নেই।